Preface
If you are running Oracle RAC, then configuring the shared storage is one of the main preinstallation tasks that needs to be done. You need to configure multipathing and make sure that the device name that will be used for ASM is always the same. And you must set permissions and ownership for these devices. On Linux you can use ASMlib for that. It stamps the devices so that it can identify them, provides an unique and consistent name for ASM and sets propper permissions for the devices. But it still possible for other processes to write to these devices, using “dd” for instance.
Now there is Oracle Grid Infrastructure 12c which introduces a replacement for ASMlib called ASM Filter Driver (AFD). Basically it does the same things as ASMlib but in addition to that it is able to block write operations from other processes than Oracle’s own ones.
So that is a good thing and I wanted to use it for a new cluster that I should set up. And that is where the trouble starts. Beside the fact that there were some bugs in the initial versions of AFD from which most got fixed by the April 2016 PSU, AFD is installed as part of Grid Infrastructure. You can read that in the Automatic Storage Management Docs. It states the following:
After installation of Oracle Grid Infrastructure, you can optionally configure Oracle ASMFD for your system.
What? After installation? But I need it right from the beginning to use it for my initial disk group. How about that? There is a MOS note How to Install ASM Filter Driver in a Linux Environment Without Having Previously Installed ASMLIB (Doc ID 2060259.1) but this Whitepaper also asumes that Grid Infrastructure is already installed.
But as you can read from this blog posts title, there is a way to use AFD from scratch, but it is not really straight forward.
1. Install Grid Infrastructure Software
First step is to install Grid Infrastructure as a software only installation. That implies that you have to do it on all nodes that should form the future cluster. I did that on the first node, saved the response file and did a silent install on the other nodes.
[oracle@vm140 ~] ./runInstaller -silent -responseFile /home/oracle/stage/grid/grid.rsp -ignorePrereq
At the end of the installation you need to run the “orainstRoot.sh” script which itself provides two other root scripts which configure either a cluster or a stand alone server:
[root@vm140 ~]# /u01/app/oraInventory/orainstRoot.sh
Changing permissions of /u01/app/oraInventory.
Adding read,write permissions for group.
Removing read,write,execute permissions for world.
Changing groupname of /u01/app/oraInventory to oinstall.
The execution of the script is complete.
[root@vm140 ~]# /u01/app/12.1.0.2/grid/root.sh
Performing root user operation.
The following environment variables are set as:
ORACLE_OWNER= oracle
ORACLE_HOME= /u01/app/12.1.0.2/grid
Enter the full pathname of the local bin directory: [/usr/local/bin]:
Copying dbhome to /usr/local/bin ...
Copying oraenv to /usr/local/bin ...
Copying coraenv to /usr/local/bin ...
Creating /etc/oratab file...
Entries will be added to the /etc/oratab file as needed by
Database Configuration Assistant when a database is created
Finished running generic part of root script.
Now product-specific root actions will be performed.
To configure Grid Infrastructure for a Stand-Alone Server run the following command as the root user:
/u01/app/12.1.0.2/grid/perl/bin/perl -I/u01/app/12.1.0.2/grid/perl/lib -I/u01/app/12.1.0.2/grid/crs/install /u01/app/12.1.0.2/grid/crs/install/roothas.pl
To configure Grid Infrastructure for a Cluster execute the following command as oracle user:
/u01/app/12.1.0.2/grid/crs/config/config.sh
This command launches the Grid Infrastructure Configuration Wizard. The wizard also supports silent operation, and the parameters can be passed through the response file that is available in the installation media.
For the moment, we do not run any of these scripts.
2. Patching Grid Infrastructure software
Next step is to patch GI software to get the latest version for AFD. Simply update OPatch on all nodes and use “opatchauto” to patch GI home. You need to specify the ORACLE_HOME path using “-oh” parameter to patch an unconfigured Grid Infrastructure home.
[root@vm140 ~]# export ORACLE_HOME=/u01/app/12.1.0.2/grid
[root@vm140 ~]# export PATH=$ORACLE_HOME/OPatch:$PATH
[root@vm140 ~]# opatch version
OPatch Version: 12.1.0.1.12
OPatch succeeded.
[root@vm140 ~]# opatchauto apply /home/oracle/stage/22646084 -oh $ORACLE_HOME
[...]
--------------------------------Summary--------------------------------
Patching is completed successfully. Please find the summary as follows:
Host:vm140
CRS Home:/u01/app/12.1.0.2/grid
Summary:
==Following patches were SUCCESSFULLY applied:
Patch: /home/oracle/stage/22646084/21436941
Log: /u01/app/12.1.0.2/grid/cfgtoollogs/opatchauto/core/opatch/opatch2016-06-10_13-54-11PM_1.log
Patch: /home/oracle/stage/22646084/22291127
Log: /u01/app/12.1.0.2/grid/cfgtoollogs/opatchauto/core/opatch/opatch2016-06-10_13-54-11PM_1.log
Patch: /home/oracle/stage/22646084/22502518
Log: /u01/app/12.1.0.2/grid/cfgtoollogs/opatchauto/core/opatch/opatch2016-06-10_13-54-11PM_1.log
Patch: /home/oracle/stage/22646084/22502555
Log: /u01/app/12.1.0.2/grid/cfgtoollogs/opatchauto/core/opatch/opatch2016-06-10_13-54-11PM_1.log
OPatchAuto successful.
You see that with the latest OPatch version there is no need to create an ocm.rsp resopnse file anymore.
3. Configure Restart
Configure Restart? Why? Because it sets up everything we need to use AFD but does not need any shared storage or other cluster related things like virtual IPs, SCANs and so on.
Therefore you use the script that was provided earlier by the “orainstRoot.sh” script. Do that on all nodes of the future cluster.
[root@vm140 ~]# /u01/app/12.1.0.2/grid/perl/bin/perl -I/u01/app/12.1.0.2/grid/perl/lib -I/u01/app/12.1.0.2/grid/crs/install /u01/app/12.1.0.2/grid/crs/install/roothas.pl
4. Deconfigure Restart
After Restart was configured, you can deconfigure it right away. Everything that is needed for AFD is being kept. The documentation for that is here.
[root@vm140 ~]# cd /u01/app/12.1.0.2/grid/crs/install/
[root@vm140 install]# ./roothas.sh -deconfig -force
5. Confiure ASM Filter Driver
Now you can finally start configuring AFD. The whitepaper from the MOS note mentioned at the beginning provides a good overview of what has to be done. Simply connect as “root”, set the environment and run the following:
[root@vm140 install]# $ORACLE_HOME/bin/asmcmd afd_configure
Connected to an idle instance.
AFD-627: AFD distribution files found.
AFD-636: Installing requested AFD software.
AFD-637: Loading installed AFD drivers.
AFD-9321: Creating udev for AFD.
AFD-9323: Creating module dependencies - this may take some time.
AFD-9154: Loading 'oracleafd.ko' driver.
AFD-649: Verifying AFD devices.
AFD-9156: Detecting control device '/dev/oracleafd/admin'.
AFD-638: AFD installation correctness verified.
Modifying resource dependencies - this may take some time.
ASMCMD-9524: AFD configuration failed 'ERROR: OHASD start failed'
[root@vm140 install]# $ORACLE_HOME/bin/asmcmd afd_state
Connected to an idle instance.
ASMCMD-9526: The AFD state is 'LOADED' and filtering is 'DISABLED' on host 'vm140'
Don’t care about the error and the message that is telling it failed. That is simply because there is no cluster at all at the moment.
As a final configuration step you need to set the discovery string for AFD so that it can find the disks you want to use. This is defined inside “/etc/afd.conf”:
[root@vm140 install]# cat /etc/afd.conf
afd_diskstring='/dev/xvd*'
The above steps need to be done on all servers of the future cluster.
Now that AFD is configured, you can start labeling your disks. Do this on only one node:
[root@vm140 install]# $ORACLE_HOME/bin/asmcmd afd_label GI /dev/xvdb1
Connected to an idle instance.
[root@vm140 install]# $ORACLE_HOME/bin/asmcmd afd_label DATA /dev/xvdc1
Connected to an idle instance.
[root@vm140 install]# $ORACLE_HOME/bin/asmcmd afd_label FRA /dev/xvdd1
Connected to an idle instance.
[root@vm140 install]# $ORACLE_HOME/bin/asmcmd afd_lsdsk
Connected to an idle instance.
--------------------------------------------------------------------------------
Label Filtering Path
================================================================================
GI DISABLED /dev/xvdb1
DATA DISABLED /dev/xvdc1
FRA DISABLED /dev/xvdd1
On all the other nodes just do a rescan of the disks:
[root@vm141 install]# $ORACLE_HOME/bin/asmcmd afd_scan
Connected to an idle instance.
[root@vm141 install]# $ORACLE_HOME/bin/asmcmd afd_lsdsk
Connected to an idle instance.
--------------------------------------------------------------------------------
Label Filtering Path
================================================================================
GI DISABLED /dev/xvdb1
DATA DISABLED /dev/xvdc1
FRA DISABLED /dev/xvdd1
That’s it.
6. Configure cluster with AFD
Finally, you can start configuring your new cluster and use AFD disks right from the beginning. You can now use the Cluster Configuration Assistant that was mentioned by “orainstRoot.sh” to set up your cluster.
[oracle@vm140 ~]$ /u01/app/12.1.0.2/grid/crs/config/config.sh
Follow the steps and you will see the well-known screens for setting up a cluster. At the point when you define the initial Grid Inftrastructure diskgroup you can now specify the “Discovery String”:
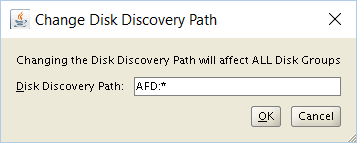
And, voila, you see the previously labeled disks:

And after you run the root scripts on all nodes, you’ll get a running cluster:
[root@vm140 bin]# ./crsctl stat res -t
--------------------------------------------------------------------------------
Name Target State Server State details
--------------------------------------------------------------------------------
Local Resources
--------------------------------------------------------------------------------
ora.ASMNET1LSNR_ASM.lsnr
ONLINE ONLINE vm140 STABLE
ONLINE ONLINE vm141 STABLE
ONLINE ONLINE vm142 STABLE
ONLINE ONLINE vm143 STABLE
ora.GI.dg
ONLINE ONLINE vm140 STABLE
ONLINE ONLINE vm141 STABLE
ONLINE ONLINE vm142 STABLE
OFFLINE OFFLINE vm143 STABLE
ora.LISTENER.lsnr
ONLINE ONLINE vm140 STABLE
ONLINE ONLINE vm141 STABLE
ONLINE ONLINE vm142 STABLE
ONLINE ONLINE vm143 STABLE
ora.net1.network
ONLINE ONLINE vm140 STABLE
ONLINE ONLINE vm141 STABLE
ONLINE ONLINE vm142 STABLE
ONLINE ONLINE vm143 STABLE
ora.ons
ONLINE ONLINE vm140 STABLE
ONLINE ONLINE vm141 STABLE
ONLINE ONLINE vm142 STABLE
ONLINE ONLINE vm143 STABLE
--------------------------------------------------------------------------------
Cluster Resources
--------------------------------------------------------------------------------
ora.LISTENER_SCAN1.lsnr
1 ONLINE ONLINE vm140 STABLE
ora.MGMTLSNR
1 ONLINE ONLINE vm140 169.254.231.166 192.
168.1.1,STABLE
ora.asm
1 ONLINE ONLINE vm140 Started,STABLE
2 ONLINE ONLINE vm142 Started,STABLE
3 ONLINE ONLINE vm141 Started,STABLE
ora.cvu
1 ONLINE ONLINE vm140 STABLE
ora.mgmtdb
1 ONLINE ONLINE vm140 Open,STABLE
ora.oc4j
1 ONLINE ONLINE vm140 STABLE
ora.scan1.vip
1 ONLINE ONLINE vm140 STABLE
ora.vm140.vip
1 ONLINE ONLINE vm140 STABLE
ora.vm141.vip
1 ONLINE ONLINE vm141 STABLE
ora.vm142.vip
1 ONLINE ONLINE vm142 STABLE
ora.vm143.vip
1 ONLINE ONLINE vm143 STABLE
--------------------------------------------------------------------------------
And that’s it. Nothing more to do. Beside creating more disk groups and setting up databases. But that is simple compared to what we’ve done till now.

